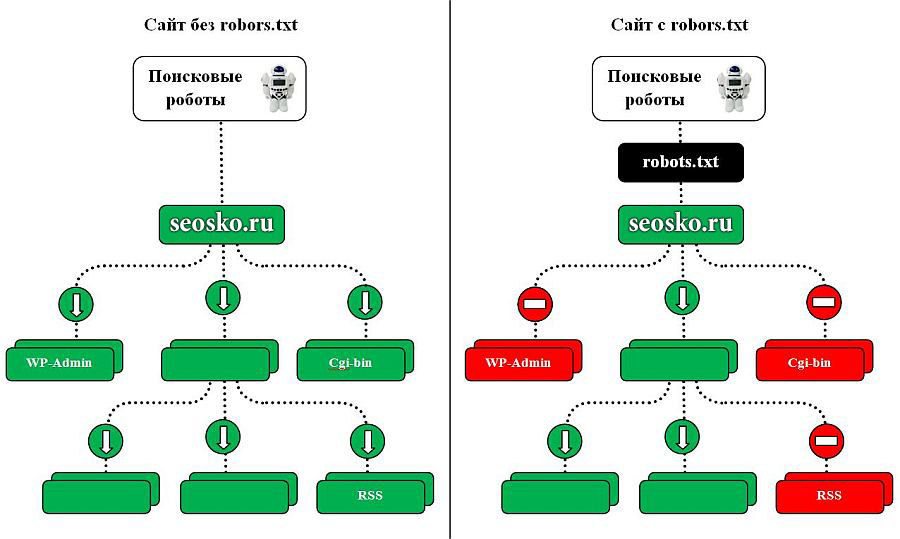
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:
Исключения Яндекса
Стандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:
User-agent: *
Для конкретного бота:
User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:
user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Следующие ссылки будут закрыты от индексации:
http://site.ru/?s=
http://site.ru/?s=keyword
http://site.ru/page/?s=keyword
http://site.ru/category/
Следующие ссылки будут открыты для индексации:
http://site.ru/category/cat1/
http://site.ru/category-folder/
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site.ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:
Host: site.ru
Пример 2:
Host: https://site.ru
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:
Crawl-delay: 3
Пример 2:
Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Пример 1:
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Пример 2:
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: *
Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif User-agent: Yandex Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif Clean-Param: utm_source&utm_medium&utm_campaign Crawl-Delay: 0.5 Sitemap: https://site.ru/sitemap.xml Host: https://site.ru
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
В этой статье я подробно раскрою процесс работы с Google Core Web Vitals для качественной технической оптимизации сайта. А также…
В этой статье я приведу перечень пунктов, которые необходимо проверить, чтобы предусмотреть все основные ключевые факторы, которые важны при оптимизации…
В интернете можно найти много публикаций на тему, как составить лучший (или даже самый лучший) файл robots.txt для Wordpress. При…
Интервью для проекта газеты Комсомольская Правда «Образование в России и за рубежом». (далее…)
С ноября 2020 года поисковый робот Google, который индексирует сайты в интернете, начнет производить сканирование по протоколу HTTP/2. Если ваш…
Наверное, я не слишком ошибусь, если скажу, что скоро будет 10 лет мифу о том, что «SEO умерло». Тем не…
{kind=link}
Показать комментарии
А почему в User-agent: * не прописаны:
Allow: /*/*.js
Allow: /*/*.css
Allow: */uploads
Конкретно в этой статье приведен базовый robots.txt для сайтов, которые могут быть на совершенно разных движках (CMS). Вы его можете взять за основу и дорабатывать под особенности вашего конкретного сайта. Не обязательно, что у вас будет папка /uploads/ для изображений. Где-то это может быть /files/ или /images/ или вообще какое-то специфическое месторасположение. Где-то, возможно, вы вообще никак не закрываете от индексирования папки с изображениями, JS и CSS, и вам не стоит беспокоиться, чтобы их открыть отдельно.
Кстати, на некоторых CMS недостаточно двух уровней вложенности для правил вида Allow: /*/*.js - нужно увеличивать - например, Allow: /*/*/*.js - чтобы все JS, CSS и изображения индексировались.
Все это проверяйте в системах вебмастер тех поисковых систем, под которые продвигаете сайт.
Добрый вечер! Очень прошу помощи! Я не асс в деле настройки сайтов. Обратились к девушке, нашли объявление в интернете, она за очень немаленькую сумму сайт сделала, но аже основные параметры не настроила, я сама как могла сайт настроила, потому что трафика входящего вообще не было, но вот с robot.txt испытала сложность. Помогите пож-та правильно сформировать robot.txt .
Мария, в разделе Контакты https://seogio.ru/kontakty/ есть информация, как со мной можно связаться.
Услуги по настройке файла robots.txt недорогие. Конечно, если его вообще нужно изменять. Трафик на ваш сайт может быть низким не из-за robots.txt. Но если файл все-таки некорректный, то это может сильно повлиять на продвижение сайта.
Как убрать из индекса архивные записи 2014/09 и метки я так понимаю /tag/blog ?
С помощью правила Disallow.
Указываете часть URL, общую для ссылок, которые нужно закрыть.
Только проверьте, чтобы вы таким образом не закрыли нужные URL.
У каждого сайта могут быть нюансы, поэтому нужно все предварительно проверить.
Не совсем понял. Есть ссылки с разными окончаниями . Какая тут общая часть, http:// vandruem. com/ 2014/09
http:// vandruem. com/ 2018/01
Добавьте:
Disallow: /2014/
Disallow: /2015/
Disallow: /2016/
Disallow: /2017/
Disallow: /2018/
Disallow: /2019/
Disallow: /2020/
Но вот так лучше не делать:
Disallow: /20
Так закроете другие URL, например, такого вида: site.ru/20-sposobov-kak-prodat-slona/
Елена, для страниц пагинации лучше настройте canonical
https://seogio.ru/meta-tegi/
Добрый день,есть вопрос;вы не по можете составить файл robots для кино сайта движок instantCMS 2,пробовал сам ставить готовые,была перегрузка сервера,потом вставил ваш пример файла Clean-param,нагрузка упала,но вскоре упал и трафик,у меня опыта очень мало,помогите услуги оплачу,с уважением Михаил.
Михаил, добрый день!
Просто так копировать нельзя - нужно смотреть, что нужно закрывать от индексирования, а что, наоборот, должно быть открыто для роботов.
Clean-param не мог повлиять на трафик. Если только закрыли индексирование какого-то раздела через Disallow. Либо вообще другие причины, не связанные с robots.txt
Можете мне написать на почту, контакты здесь: https://seogio.ru/kontakty/
Похоже на правду.
Но такие вещи нужно всегда проверять через яндекс или гугл вебмастер. Там есть специальный раздел для проверки robots.txt. Для проверки можете указать как реальные, так и выдуманные ссылки.
Добрый день. Может поможете в таком вопросе ?
Добрый день. Может поможете в таком вопросе ? В корне сайта почему-то нет этого файла. Когда создаю новый, с помощью инструмента гугл и помещаю его в корень, он тут же исчезает. Исчезает и сам сайт из поиска. После повторной индексации появляется, но ненадолго. Это в гугле. В яндексе всё в порядке. Недавно, в админке я закрывал на несколько дней сайт для индексации. Может это внесло сбой ?
Олег, это вопрос к разработчику сайта.
Обычно такого не происходит. Но бывают специфические CSM или плагины для них, из-за которых настройка robots.txt происходит по-другому. Как - надо, чтобы смотрел программист, который делал сайт.
Спасибо. Будем решать.
Отличная статья, спасибо!
мерси!